 Татьяна Лазарева,SEO-специалист
Татьяна Лазарева,SEO-специалистДубли страниц на сайте: каких бывают видов, откуда берутся и как их удалить

Дубли — это страницы сайта, расположенные под одним доменом, контент на которых целиком или частично совпадает с другими. Любопытно, что дублирование встречается практически на трети всех существующих веб-сайтов. Проверка на дублирование будет полезна как тем IT-специалистам, у которых уже есть действующий сайт, так и тем, кто только собирается его запускать.
Виды дублей страниц на сайте
Дубли веб-страниц возникают в силу различных обстоятельств, поэтому их следует рассматривать по нескольким видам.
Полные
С «www» и без, «http» и «https», слеши в середине, в конце ссылки, их отсутствие К этому виду относятся одинаковые страницы, которые можно открыть по нескольким ссылкам. Отличие таких URL в том, есть ли в начале адреса «www», указан протокол «http» или «https», сколько слешей стоит в середине или конце.
Главная страница открывается по разным адресам Например, когда URL, который содержит в конце название индексного файла с расширением или без него — «https://domain.com/index.php», «https://domain.com/index.html», «https://domain.com/index» — открывает одну и ту же страницу.
С UTM-метками UTM-метки — это специальные параметры внутри ссылки, необходимые системам веб-аналитики для отслеживания эффективности продвижения страниц. Порой в поисковой выдаче могут встречаться страницы с UTM-метками, которые полностью повторяют содержимое других веб-страниц без меток.
Дублирование товара/услуги Причина появления таких дубликатов — человеческий фактор. Например, один товар или услуга по ошибки были помещены в разные категории. Как результат — снижение перехода на дублирующийся продукт.
По уровням вложенности К этому виду причисляются веб-страницы, которые открываются по адресам с разным уровнем вложенности, например: «https://flowerstore.com/flowers/roses» и «https://flowerstore.com/roses». Такие различия могут возникать из-за особенностей CMS, в которой осуществлялась разработка веб-сайта.
Не настроена страница для 404 ошибки Если ответ сервера для ошибки 404 не настроен или настроен некорректно, то, при изменении в URL регистра символов, замены дефисов на нижнее подчеркивание, добавление лишних символов, содержимое страницы не изменится.
Версии для печати Если у страницы есть версия для печати и она открывается как идентичная оригиналу версия с измененной ссылкой — это тоже дубликат.
Частичные
Товары с одинаковыми характеристиками Раньше на веб-сайтах интернет-магазинов можно было часто заметить, как при выборе другого цвета или размера товара открывается новая страница. Именно так появляются частичные дубли страниц этого вида. Выход из этой ситуации — добавление на страницу селектора, который, при выборе иной характеристики товара, позволит вывести ее на той же странице без открытия новой.
Страницы сортировок, фильтров Повторы страниц в этом случае могут возникать при фильтрации по каталогу, когда каждый новый выбранный параметр сортировки отражается в ссылке.
Региональные версии страниц Здесь примером могут являться web-страницы, URL которых меняется в зависимости от выбора региона — а контент при этом остается прежним.
Откуда берутся дубли страниц и почему от них нужно избавляться
Дубликаты страниц могут создаваться по разным причинам:
Особенности CMS — к примеру, выбранная для создания сайта CMS не позволяет добавлять на страницы возможность выбора товара по разным характеристикам без изменения ссылки. В этом случае по каждому параметру будет отдельная страничка-дубль.
Ошибки, допущенные человеком, нередко становятся причиной повторяющихся страниц. К таким ошибкам относятся случаи, когда, например, контент-менеджер заносит услугу или товар в несколько разных категорий, или IT-специалист меняет URL у продукта, но по старому URL продукт все еще доступен.
Почему нужно удалять дубли, чем они опасны — давайте разберемся:
Поисковые системы могут неправильно идентифицировать релевантную страницу — а именно, поместить в поисковую выдачу дубликат, а не оригинал веб-страницы. Для пользователя, который ищет ответ на свой вопрос в поисковой системе, дублирование не представляет опасности, но для SEO-специалиста такие случаи создают много проблем.
Как следствие — трафик разделяется между всеми дубликатами страниц, что мешает закреплению определенной страницы в топе поисковой системы.
Снижается скорость обхода и индексирования — поисковики медленнее анализируют контент сайта из-за обилия дублей, за счет чего нужные страницы реже появляются в выдаче.
Как обнаружить дубли страниц
Теперь, когда понятен риск наличия дублей web-страниц, необходимо проверить сайт. Обнаружить дубликаты можно с помощью:
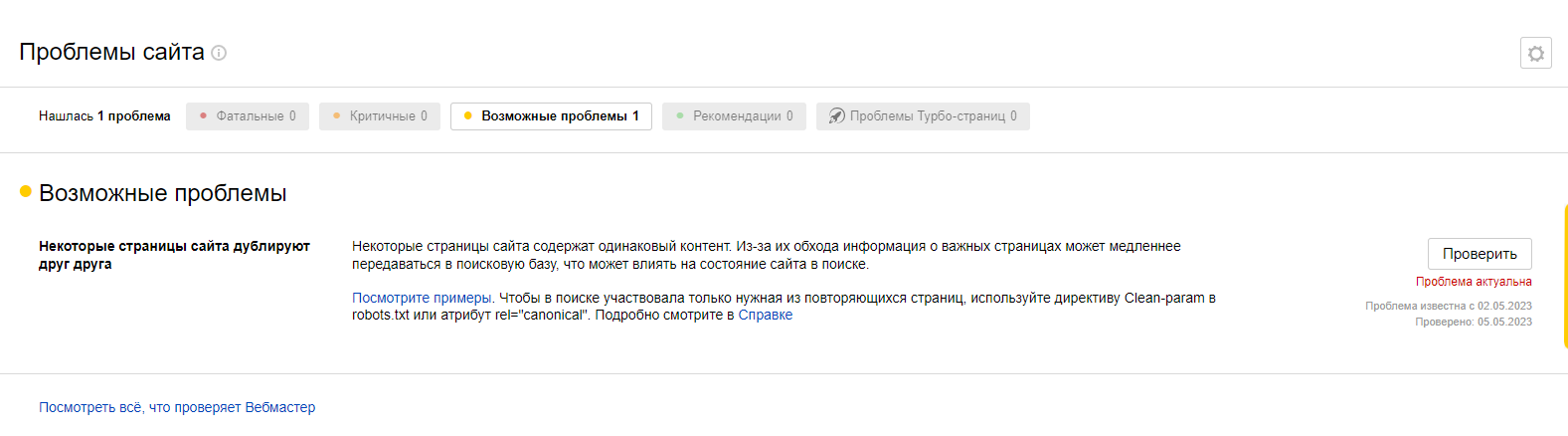
Специальных сервисов и программ — Яндекс.Вебмастер, Google Search Console Яндекс.Вебмастер сообщит о дубликатах страниц в возможных проблемах, а также предложит варианты решения
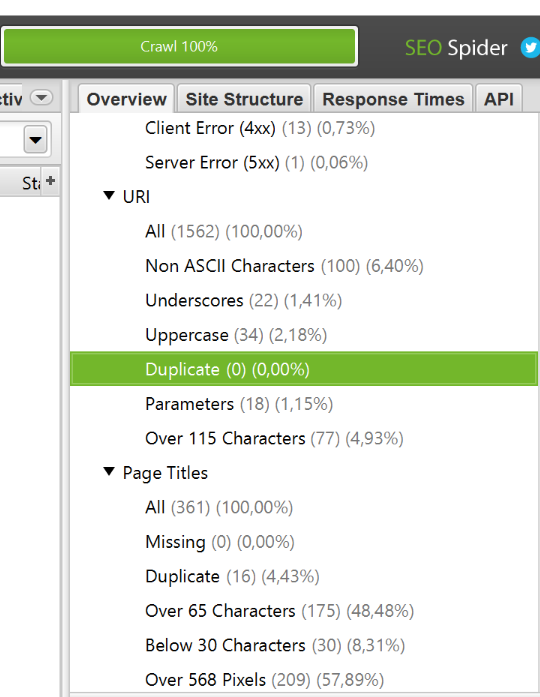
Screaming Frog SEO Spider, SiteAnalyzer Программа Screaming Frog SEO Spider позволяет найти дублирующиеся веб-страницы по различным параметрам (например, по совпадающему тегу title).
Операторов Довольно медленный способ, который применяется, если нет доступа к специализированным сервисам или программам. Минус этого метода также заключается в том, что дубликаты с помощью него можно найти только в том случае, если они уже индексированы поисковой системой. Пример поиска через операторы: ввести в поисковике запрос «site:*хост* "фраза для проверки"», в которой "фраза для проверки" — любой текст со страницы сайта.
Как избавиться от дублей
Когда дубликаты страниц удалось найти, необходимо избавиться от них. Удаление дублирующий web-страниц можно осуществить по-разному:
Склеить дубли через 301 редирект Суть этого метода заключается в том, чтобы выбрать основную страницу и настроить перенаправление со всех существующих дубликатов на нее. Доступ к идентичным страницам в этом случае будет потерян, но поисковые системы станут вести пользователя на ту страницу сайта, которую вы определили главной.
Запретить индексацию дублей Например, заблокировать дубли в robots.txt. Для этого текстовый файл robots.txt нужно поместить в корень веб-сайта — он будет сообщать поисковым системам, что такие страницы индексировать не нужно. Минус использования файла в том, что поисковиками он будет расцениваться скорее как рекомендация, чем как указание. Эффективнее действует использование метатега robots в элементе head кода вашего сайта. Поисковики будут идентифицировать этот метатег как команду и перестанут показывать дублирующие страницы.
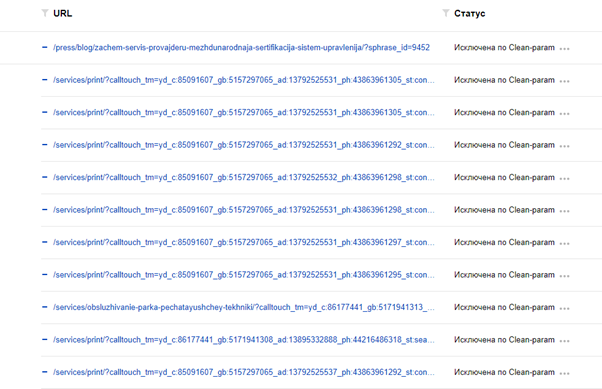
Через Clean-param (работает только для Яндекса): Clean-param: auth_token>m_debug, Clean-param: calltouch_tm Директива Clean-param, внесенная в robots.txt, будет указывать поисковому роботу Яндекса, что повторяющиеся страницы не стоит загружать многократно. Впоследствие все страницы робот Яндекса объединит под один адрес, который и будет выводить в поисковой выдаче.
Не пренебрегайте проверкой на дубли страниц ваш сайт, ведь время, потраченное на это, позволит вам в будущем эффективнее работать над продвижением страниц в интернете. Если вы еще не запустили веб-сайт, добавьте в план запуска пункт о проверке ресурса на дубликаты. Если сайт уже работает и не является столь продуктивным, насколько вы бы хотели — выделите время и средства, необходимые для проверки и удаления дублирующихся веб-страниц. И даже в случае, если продвижение портала не приносит вам проблем и вы считаете его успешным, уделите внимание дублям страниц все равно — вполне возможно, что вы можете повысить эффективность раскрутки сайта и получить гораздо больше выгоды, чем планировали. Успешного продвижения!