 Сергей Асминкин,SEO-специалист
Сергей Асминкин,SEO-специалистSEO фильтры интернет-магазина: как управлять техническими ограничениями каталога без потери трафика
Фильтры товаров - это то место, где большинство интернет-магазинов совершают свою главную SEO-ошибку. Настройка каталога интернет-магазина без правильного управления фильтрами превращает сайт с 2 000 реальных страниц в монстра из 200 000 URL - большинство из которых поисковик воспринимает как дубли и тратит на них краулинговый бюджет вместо обхода реальных страниц. Именно это я нахожу при аудите у 8 из 10 магазинов. Статья - часть блока об настройке каталога интернет-магазина и разбирает фильтры с технической стороны: какие URL создавать, какие закрывать, какими методами и как проверить результат.
Объясняю принципы понятным языком - без предположения, что читатель знает, что такое robots.txt. Но и без упрощений, которые убивают практическую пользу.
Почему фильтры - главная техническая проблема крупного каталога
Краулинговый бюджет - это ресурс, который поисковый робот выделяет сайту для обхода страниц. У среднего интернет-магазина бюджет позволяет обходить 5 000-20 000 страниц в день. Если каталог сгенерировал 300 000 URL через фильтры - робот тратит недели только на них, а новые карточки товаров и категории ждут индексации месяцами.
Математика фильтров работает так: магазин с 1 000 товарами имеет фильтры по бренду (20 значений), цвету (10), размеру (15) и материалу (8). Без управления индексацией: 20 × 10 × 15 × 8 = 24 000 комбинаций только от четырёх фильтров. Добавим сортировку (5 вариантов) и пагинацию (в среднем 10 страниц) - уже 1,2 миллиона URL. Реальных страниц с уникальным контентом - 1 000.
Результат предсказуем: поисковик видит миллион страниц с одинаковым контентом (разные комбинации фильтров показывают те же товары), воспринимает их как дублированный контент и снижает авторитет домена. Позиции падают по всему сайту, не только по страницам фильтров.
Масштаб проблемы: сколько дублей создаёт ваш каталог
Масштаб проблемы зависит от двух факторов: размера каталога и количества атрибутов фильтрации. Таблица показывает типичную картину.
| Размер каталога | Параметры фильтра | Потенциальные дубли | Оценка риска |
|---|---|---|---|
| 500 товаров | 3 атрибута фильтра | до 2 000 страниц | Средний риск. Настройка занимает 1-2 дня. |
| 2 000 товаров | 5 атрибутов фильтра | 10 000-50 000 страниц | Высокий риск. Краулинговый бюджет исчерпан. Настройка 3-5 дней. |
| 5 000 товаров | 7 атрибутов фильтра | 100 000-500 000 страниц | Критический риск. Реальные страницы не индексируются. Нужна архитектурная работа. |
| 10 000+ товаров | 10+ атрибутов | 1 000 000+ страниц | Проблема масштаба. Без системной настройки фильтров SEO не работает совсем. |
Для небольшого магазина с 200-500 товарами проблема некритична - поисковик справляется с небольшим количеством дублей. Для магазина от 2 000 товаров настройка фильтров становится обязательной - без неё SEO-продвижение разделов работает в 3-4 раза хуже.
| 🔗 Как устроена оптимизация страниц категорий в вашем каталоге: Продвижение страниц категорий |
Решение для каждого типа фильтра: полная таблица
Ключевой принцип оптимизации фильтров: фильтр индексируется (превращается в SEO-страницу), если по нему есть реальный поисковый спрос. Всё остальное - закрыть от индексации. Детальные решения по типам:
| Тип фильтра | Решение | URL-стратегия | Детали реализации |
|---|---|---|---|
| Один атрибут (бренд, цвет, размер) с частотой >200/мес | SEO-страница | Уникальный URL + контент | Создать чистый ЧПУ, написать мини-текст 400-600 знаков, уникальный title. Передаёт ссылочный вес и приносит самостоятельный трафик. |
| Один атрибут с частотой 50-200/мес | Анализ конкурентов | По ситуации | Проверить топ-10 выдачи: если конкуренты делают SEO-страницы — создавать. Если нет — noindex. |
| Один атрибут с частотой <50/мес | noindex + canonical | Закрыть от индексации | Трафика нет, дубли создаются. Canonical на базовую категорию + noindex на странице фильтра. |
| Ценовой диапазон (от-до) | noindex + canonical | Закрыть всегда | Бесконечное число комбинаций. Закрыть через robots.txt параметры или meta noindex без исключений. |
| Сортировка (по цене, дате, рейтингу) | noindex + canonical | Закрыть всегда | UX-функция, не поисковая. Добавить canonical на базовую категорию. Параметры сортировки в robots.txt. |
| Комбинация двух атрибутов | Оценить частоту | Обычно noindex | «Синие Nike 42 размера» - суммарная частота редко превышает 50. Как правило, закрывать от индексации. |
| Комбинация трёх+ атрибутов | noindex + canonical | Закрыть всегда | Экспоненциальное число URL. Даже при наличии спроса создание SEO-страниц экономически нецелесообразно. |
| Наличие / «В наличии» | noindex + canonical | Закрыть всегда | Динамический параметр. Страница «диваны в наличии» сегодня будет другой завтра. Не индексировать. |
Как определить порог «частота >200/мес»: это минимальная частотность в Яндекс.Вордстате, при которой создание отдельной SEO-страницы экономически оправдано. При меньшей частотности трафик с такой страницы не окупит затраты на её создание и поддержку. Порог условный: для высокомаржинальных товаров он может быть 50/мес, для низкомаржинальных - 500/мес.
Практический способ быстро оценить потенциал фильтра: введите в
Яндекс.Вордстатзапрос «[категория] [значение фильтра]». Посмотрите точную частотность (в кавычках) и широкую (без).Если точная частота выше 100 — фильтр заслуживает
SEO-страницы. Если ниже 30 — закрывайте без сомнений. Диапазон 30–100 — анализируйте конкурентов: если в ТОП-5 есть страницы именно под этот запрос — создавайте, если нет — закрывайте.
Методы управления индексацией фильтров: сравнение подходов
Существует несколько технических способов управлять тем, что поисковик видит и что индексирует. У каждого - своя область применения.
| Метод | Скорость настройки | Гибкость | Когда применять |
|---|---|---|---|
| robots.txt Disallow | Высокая | Отличная | Быстро, работает на уровне сервера. Блокирует целые паттерны URL (Disallow: /*?sort=). Но: роботу не объясняет, что страница существует и имеет canonical. Не подходит для страниц, которые нужно разрешить для рендеринга. |
| meta robots noindex | Средняя | Хорошая | Тонкая настройка: закрывает конкретные страницы. Поисковик видит страницу, но не индексирует. Требует изменений на уровне шаблона CMS. Лучший выбор для гибкого управления. |
| canonical на базовую категорию | Средняя | Хорошая | Передаёт ссылочный вес на главную страницу категории. Поисковик воспринимает фильтрованную страницу как дубль базовой. Хорошо сочетается с meta noindex. |
| Параметры URL в Search Console | Средняя | Средняя | Инструмент GSC «Параметры URL» позволяет указать, как обрабатывать параметры. Работает только для Google. Для Яндекса - аналог в Вебмастере. Не блокирует, только подсказывает. |
| AJAX-фильтрация без изменения URL | Высокая | Идеальная | Фильтры работают через JavaScript без смены URL. Дублей нет по определению. Минус: сложнее реализовать, требует дополнительной работы для доступности краулером. |
| ЧПУ для SEO-страниц фильтров | Средняя | Отличная | Создаём чистые URL для ценных фильтров: /catalog/divany/seryy/. Всё остальное - через параметры с noindex. Позволяет совместить SEO-страницы и закрытие от индексации одновременно. |
Рекомендуемая комбинация методов
На практике ни один метод не работает в изоляции. Профессиональная настройка фильтров интернет-магазина строится на комбинации:
- robots.txt - закрывает параметры сортировки и очевидно ненужные группы URL по паттерну.
- meta noindex + canonical - для фильтрованных страниц с низкочастотными комбинациями.
- ЧПУ - для ценных SEO-страниц фильтров с частотностью выше 200.
- AJAX-фильтрация - для UX-функций (цена, наличие), которые вообще не должны менять URL.
Такая комбинация позволяет одновременно: давать пользователю удобную фильтрацию, создавать SEO-страницы под ценные запросы и не допускать взрывного роста дублированных URL.
| 🔗 Нужна помощь с настройкой фильтров? Разбираем SEO карточки товара: SEO карточки товара |
Как создать SEO-страницы фильтров: технология и контент
Если фильтр заслуживает SEO-страницы, её нужно создать правильно - иначе она либо не ранжируется, либо конкурирует с базовой категорией.
URL-структура SEO-страниц фильтров
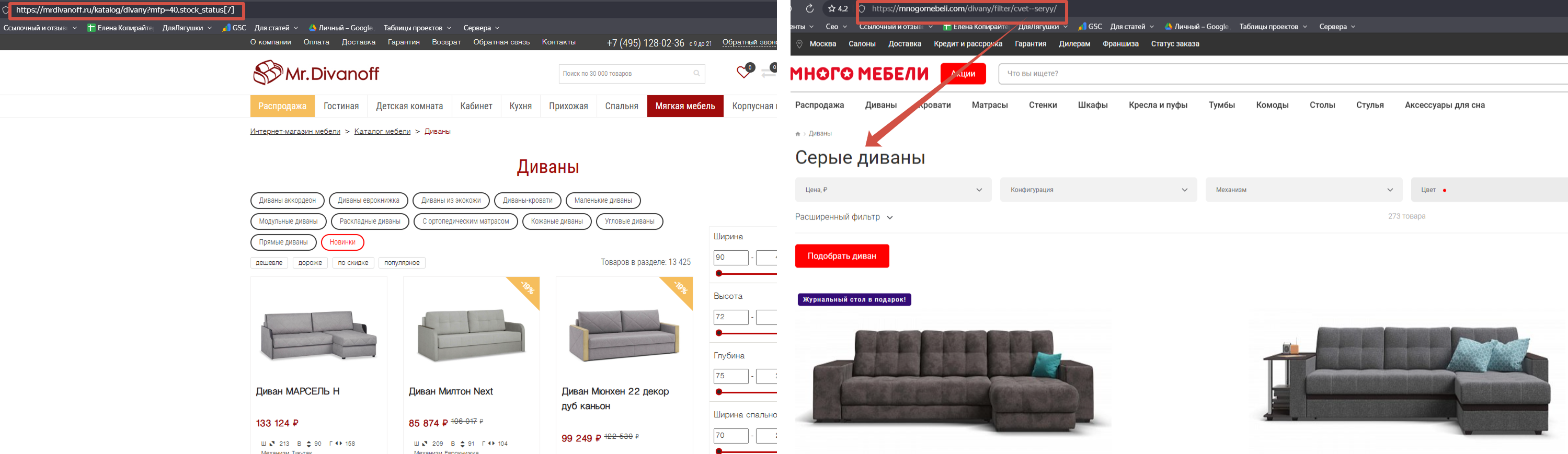
Плохой URL: /catalog/divany/?color=grey&in_stock=1. Хороший URL: /catalog/divany/seryy/. Чистый URL без параметров легче ранжируется, лучше выглядит в сниппете и не создаёт проблем при изменении параметров фильтрации.
Структура ЧПУ для фильтров зависит от архитектуры сайта. Распространённые варианты: /catalog/[категория]/[значение-фильтра]/ или /catalog/[категория]-[значение]/. Главное правило: URL однозначно идентифицирует страницу и содержит ключевое слово.
Все URL фильтров с параметрами (остаточные, для UX без SEO-статуса) должны вести через canonical на соответствующий ЧПУ или на базовую категорию. Это предотвращает ситуацию, когда один и тот же контент доступен по двум адресам.
Контент для SEO-страницы фильтра
Минимальный набор: уникальный title, уникальный H1, мини-текст 400-600 знаков. Контент отличается от базовой категории - иначе это тот же дубль, только с чистым URL.
Шаблон title для фильтра: «[Категория] [значение фильтра] купить в [Город] - цены от [Цена] ₽». Пример: «Диваны серые купить в Москве - цены от 14 900 ₽».
Мини-текст объясняет специфику фильтра: «Серые диваны подходят для интерьеров в стиле лофт и скандинавском. Нейтральный оттенок хорошо сочетается с деревянными элементами декора и белыми стенами». 400 знаков - достаточно для ранжирования по низкочастотным запросам без перегрузки страницы.
Пагинация каталога: технические ограничения и SEO-решения
Пагинация - второй по масштабу источник дублей после фильтров. Страницы /catalog/divany/?page=2, /catalog/divany/?page=10 содержат разные товары, но поисковик не всегда понимает, как их ранжировать по отношению к первой странице.
Три подхода к управлению пагинацией
Подход первый - canonical на первую страницу. Все страницы пагинации получают canonical: `<link rel='canonical' href='/catalog/divany/' />`. Поисковик воспринимает их как дубли первой страницы и передаёт ссылочный вес туда. Минус: товары со страниц 2+ теряют шансы на самостоятельное ранжирование.
Подход второй - rel=next/prev (устаревший, но работающий в Яндексе). Помогает поисковику понять последовательность страниц. Google официально отказался от этого атрибута, Яндекс продолжает его учитывать. Для российского рынка - рабочий инструмент.
Подход третий - noindex на страницы пагинации 2+. Первая страница индексируется, остальные закрыты. Краулинговый бюджет экономится. Минус: товары с глубоких страниц не попадают в индекс напрямую (только через ссылки с карточек).
Рекомендация: canonical + rel=next/prev для российского рынка. Для крупных магазинов с 50+ страницами пагинации в категориях - дополнительно noindex на страницах с 5-й и далее.
Количество товаров на странице каталога напрямую влияет на глубину пагинации. 12 товаров на странице при 360 позициях в категории = 30 страниц пагинации. 48 товаров = 8 страниц.
Увеличение количества товаров на странице — простой способ сократить пагинацию, уменьшить краулинговый бюджет на дубли и ускорить индексацию реальных страниц. Оптимум: 24–48 товаров в зависимости от скорости загрузки.
Технические ограничения разных CMS: как настроить фильтры
Возможности управления индексацией фильтров зависят от CMS. Разберём самые распространённые платформы для российского рынка.
1С-Битрикс
Битрикс имеет встроенный модуль «Поиск по сайту» и компонент умного фильтра SmartFilter. Управление canonical реализуется через настройки компонента: параметр «Адрес страницы» в свойствах фильтра. Для массовой настройки robots.txt используются правила на уровне htaccess.
Известная проблема Битрикс: SID-параметры (session ID) в URL добавляют уникальный идентификатор к каждой ссылке, создавая бесконечное число версий каждого URL. Закрывается через настройку сессий без отображения в URL или через Disallow: /*?PHPSESSID= в robots.txt.
OpenCart и ModX
В OpenCart управление параметрами URL реализуется через модули SEO-оптимизации (Nooddles SEO, SEO Pro). Без модулей URL генерируются с параметрами по умолчанию. Настройка canonical требует правки файла catalog/controller/product/category.php или установки специализированного модуля.
WooCommerce (WordPress)
WooCommerce с плагином Yoast SEO или Rank Math позволяет управлять индексацией страниц архивов и таксономий через интерфейс без кода. Плагины предоставляют настройку canonical и noindex для разных типов страниц из административной панели. Для AJAX-фильтрации рекомендуется плагин FacetWP.
Самописные решения
Самописные магазины дают полный контроль над URL и индексацией, но требуют явной реализации всех SEO-механизмов. Ключевые точки: генерация ЧПУ для SEO-страниц фильтров, шаблонизация canonical тегов, настройка robots.txt через административную панель. Без документирования этих механизмов каждое обновление кода рискует сломать настройки индексации.
[vue:start]{"text":"Хотите, чтобы фильтры вашего магазина работали на SEO, а не против него?","subtext": "Проведём технический аудит каталога: покажем, сколько страниц с дублями есть сейчас и дадим план исправлений","btnText": "заказать аудит каталога","link":"
Как проверить настройку фильтров: инструменты и метрики
После настройки фильтров нужно убедиться, что изменения работают корректно. Пять проверок, которые закрывают основные риски.
Проверка 1: количество страниц в индексе
В Google Search Console - раздел «Покрытие» - смотрим количество «Действительных» страниц. Если их значительно больше, чем реальных страниц категорий и товаров - фильтры продолжают генерировать дубли. Яндекс.Вебмастер → «Индексирование» → «Страницы в поиске» - аналогичная метрика для Яндекса.
Проверка 2: краулинг Screaming Frog
Краулинг (обход) сайта показывает, сколько URL реально существует. Экспортируем список, фильтруем по наличию параметров (?color=, ?sort=, ?page=). Если таких URL тысячи при сотнях реальных страниц - настройка нужна.
Проверка 3: тест canonical
Открываем страницу фильтра в браузере, правой кнопкой - «Просмотр кода страницы», ищем `<link rel='canonical'`. Если canonical указывает на правильный URL - настройка работает. Автоматизировать проверку canonical для сотен страниц - через Screaming Frog (колонка Canonical).
Проверка 4: краулинговый бюджет в логах
Анализ логов сервера (access.log) показывает, какие URL поисковый робот посещает чаще всего. Если 70%+ обращений робота - к страницам с параметрами фильтров, а не к реальным страницам - бюджет расходуется неэффективно. Инструменты: Screaming Frog Log Analyzer, Semrush Log File Analyzer.
Проверка 5: динамика индексации новых страниц
После настройки фильтров отслеживайте скорость индексации новых карточек товаров. Норма - 1-3 недели для новой карточки при работающем краулинговом бюджете. Если новые товары не появляются в индексе 1-2 месяца - бюджет по-прежнему расходуется на дубли.
Часто задаваемые вопросы
Как понять, что фильтры уже создали проблему с дублями?
Два быстрых способа. Первый: в Google Search Console раздел «Покрытие» - смотрим «Действительные страницы». Если их намного больше, чем категорий и карточек товаров в каталоге - дубли есть. Второй: введите в Яндекс «site:вашдомен.ru» и посмотрите количество страниц в индексе. Если цифра в разы превышает реальное количество страниц - фильтры создали дубли.
Можно ли настроить фильтры самостоятельно или нужен разработчик?
Базовые настройки - можно самостоятельно. robots.txt правится через административную панель хостинга или CMS без разработчика. Meta noindex в большинстве CMS настраивается через плагины или модули SEO без кода. Для создания ЧПУ под SEO-страницы фильтров нужен разработчик: это изменение маршрутизации URL, которое затрагивает код CMS. Для AJAX-фильтрации без смены URL - обязательно разработчик.
Сколько времени занимает исправление проблемы с дублями?
Технические настройки (robots.txt, noindex) - 2-5 дней реализации. Поисковик замечает изменения через 2-4 недели после переобхода сайта. Полное очищение индекса от дублей занимает 1-3 месяца: поисковик постепенно убирает закрытые страницы и переиндексирует приоритетный контент. Для создания SEO-страниц фильтров с уникальным контентом - ещё 1-2 месяца работы с контентом.
Что делать, если закрыли от индексации лишние страницы?
Если случайно закрыли страницы, которые должны индексироваться: убираем директиву Disallow или meta noindex, добавляем страницы в sitemap.xml и отправляем sitemap на переобход через Search Console и Яндекс.Вебмастер. Поисковик переиндексирует их в течение 1-3 недель. Для ускорения - используйте «Инструмент проверки URL» в Search Console с запросом на переобход конкретных страниц.
Есть интересная ![]() тема, кейс или профессиональный опыт? Давайте
тема, кейс или профессиональный опыт? Давайте ![]() сделаем из этого сильный
сделаем из этого сильный ![]() материал.
материал.